
Databases are a part of everybody’s daily routine, even people who do not own a computer or mobile phone interact with them regularly. When we take out money from an ATM, check our bank balance, shop online, view social media or perform almost any digital interaction, we are accessing a database.
“Probably the most misunderstood term in all of business computing is database, followed closely by the word relational” (Harrington, 2016). Thanks to a mass of misinformation, many businesspeople and technology workers are under the false impression that designing and implementing databases is a simple task that administrative staff can easily do. In reality, designing and implementing a database well is a huge challenge that requires analysis of an organisation’s needs and careful design and implementation.
Some people claim that traditional structured databases are a thing of the past. While this may be true from some perspectives (for example, for developers with websites that have millions of users in areas such as social media), for the rest of us structured databases are still very much a part of our lives. Changing requirements and the evolution of the Internet have meant that new types of databases have emerged but they have specific uses.
Databases are essentially software applications. A database management system (DBMS) is the name of the software that provides data to other applications, allowing all the digital information systems that we interact with today. Often, a DBMS is referred to as a database. There are many vendors and solutions with differing standards and uses. Data is shared with a variety of standards, but primarily they all serve the same purpose, which is to provide applications with data. The applications then process the data and turn it into something useful for the users: information.
The primary objective of the article is to define and explain databases in a way that anyone can understand. The idea of a one-size-fits-all database is impossible, and this article argues that there are different types of databases for different types of technology projects. This article explores the history of databases, looks at the differences between traditional and modern models for data storage and retrieval, and finally examines the new types of data challenges that we are facing in business intelligence and big data.
Early history of databases
Before databases existed, everything had to be recorded on paper. We had lists, journals, ledgers and endless archives containing hundreds of thousands or even millions of records contained in filing cabinets. When it was necessary to access one of these records, finding and physically obtaining the record was a slow and laborious task. There were often problems ranging from misplaced records to fires that wiped out entire archives and destroyed the history of societies, organizations and governments. There were also security problems because physical access was often easy to gain.
The database was created to try and solve these limitations of traditional paper-based information storage. In databases, the files are called records and the individual data elements in a record (for example, name, phone number, date of birth) are called fields. The way these elements are stored has evolved since the early days of databases.
The earliest systems were called the hierarchical and network models. The hierarchical model organised data in a tree-like structure, as shown in fig. 1. IBM developed this model in the 1960s.
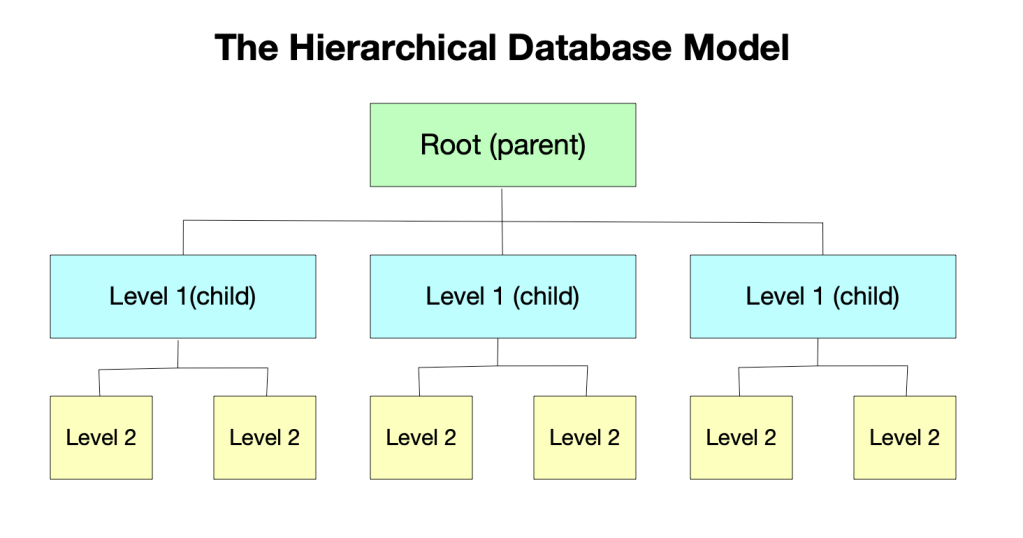
Fig. 1 The hierarchical database model
The hierarchical model represents data as records which are connected with links. Each record has a parent record, starting with the root record. This is possibly the most straightforward model to understand because we have many hierarchies in the real world – in organisations, the military, governments and even places like schools. Records in the hierarchical model contained one field. To access data using this model, the whole tree had to be traversed. These types of database still exist today and do have a place in development, despite the significant advances in the technology. They are, for example, used by Microsoft in the Windows Registry and in file systems, and they can have advantages over more modern database models (speed and simplicity). However, there are also many disadvantages, the primary being that they cannot easily represent relationships between types of data. This can be achieved through 25complex methods (using “phantom” records), but to accomplish this, the database designer has to be an expert that understands the fundamental workings of these systems.
The hierarchical database did solve many of the problems mentioned above with a paper-based system. Records could be accessed almost instantaneously. It also had a full backup and recovery mechanism that meant the problem of lost files due to damage was a thing of the past.
In 1969, scientists at the Conference on Data Systems Languages (CODASYL) released a publication that described the network model. It was the next significant innovation in databases. It overcame the restrictions of the hierarchical model. As shown in fig. 2, this model allows relationships, and it has a “schema” (a diagrammatic representation of the relationships).
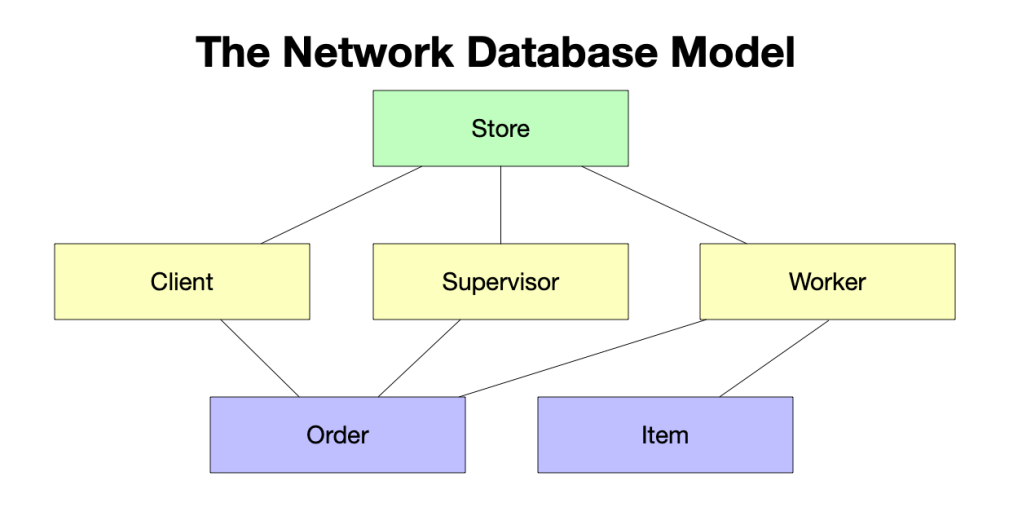
Fig. 2 The network database model
The main difference between the hierarchical model and the network model is that the network model allows each record to have more than one parent and child record. In fig. 2, the “Client”, “Supervisor” and other boxes represent what in database terminology are called entities. The network model allows entities to have relationships, just like in real life. In the example, an order involves a customer, supervisor and worker – as it would if a client walked into a store and bought a product.
The network model did improve on the hierarchical model, but it did not become dominant. The main reason for this is that IBM continued to use the hierarchical model in their more established products (IMS and DL/l) and researchers came up with the relational model. The relational model was much easier for designers to understand and the programming interface was better. The network and hierarchical models were used throughout the 1960s and 70s because they offered better performance. The mainframe computer systems used in the 60s and 70s needed the fastest possible solutions because the hardware was extremely limited. However, the 1980s saw tremendous advances in computing technology and the relational model started to become the most popular.
The relational model was, like the network model, described in a publication in 1969. The relational model describes the data in a database as being stored in tables, each containing records with fields. An example could be a customer table, which could include the following fields:
Customer:
- customer id
- first name
- last name
- street address
- city
The type of data for each field is predetermined (for example, text, number, date) and this helps ensure there are no inconsistencies and the output is what the applications need (it helps, for example, determine how to sort data). These tables can have relationships in a relational database, and different types of relationships exist. Common types include:
- One-to-One
- One-to-Many
- Many-to-Many
These allow the designer to show how one table relates to another. For example, a customer will probably buy many products. Therefore one customer can be associated with many products (this is a one-to-many relationship). These relationships also allow the database designer to ensure the database will work well when applications access it and helps with troubleshooting problems.
Relationships can be mandatory (or not), and this helps to maintain the integrity of a database. For example, if a product has to be associated with a manufacturer to exist in a database, then a rule can exist that only allows the addition of products if they have an associated manufacturer. It means that there is less scope for error when the database is deployed.
Most relational databases use a standard method for accessing the data: the Structured Query Language (SQL). SQL allows an application to gain access to the data needed by a user. It can either retrieve all the data from a table (or even a database) or just one individual field, determined by a set of criteria. For example, an application may only require the name of a professor associated with a particular course and they may not need any more data from the tables.
The main advantage of the relational model is that it provides consistency in the data. The model implements a set of constraints and these ensure that the database functions as intended. The relationships and resulting constraints are developed through studying the environment in which the database operates. It is one of the key reasons that database design is not as simple as most people think. The real-world relationships between the entities have to be determined so that the database functions correctly. This analysis involves studying the previous paper-based record systems and interviewing employees and suppliers in an organisation. Project managers or analysts have to do a strict and thorough requirement analysis before a database can be populated and used. It ensures that a system will not be able to do anything that would cause errors or incorrectly represent the real-world situation of the data.
1980-1990
Since the relational model was created in the late 1960s, it has changed little. Modern businesses still use these systems to record their day-to-day activities and to help them make critical strategic decisions. Database companies are among the largest and most profitable organisations in the world, and companies founded in the 1960s and 70s are still thriving today.
The key identifier for a traditional database is the type of data that it handles. It contains data that are consistent and in which the fundamental nature does not significantly change over time. It was more than adequate for all but the most complex types of data storage for decades.
In 1977, Larry Ellison, Bob Miner and Ed Oates formed a company in California called Software Development Laboratories (SDL) after reading about IBM’s System R Database (which was the first implementation of SQL). They aimed to create a database that is compatible with System R. In 1979 this company was renamed to Relational Software, Inc (RSI) and then finally Oracle Systems Corporation in 1982. Oracle would go on to be the biggest and most profitable database vendor in the world. They developed their software with the C programming language which meant it was high performance and could be ported to any platform that supported C.
By the 1980s, there was more competition in the market, but Oracle continued to dominate in the enterprise. Towards the end of the 80s, Microsoft developed a database for the OS/2 platform called SQL Server 1.0. In 1993, they ported this to the Windows NT platform and due to the adoption of Windows technology at the time, it became the standard for small to medium-sized businesses. The development environment that Microsoft created in the mid-to-late 90s (visual basic and then .NET) meant that anyone, not just long-term experienced developers, could harness the power of databases in their applications. By 1998, they had released SQL Server V7, and the product was mature enough to compete with the more established players in the market.
In the early 90s, there was another database created that would have a more significant effect than any other, at least for the online market. The mid-1990s brought about a revolution in software development. It came about to combat Microsoft’s dominance and tight control of the code used on most PC systems in the 90s, and the open-source movement was born. They did not believe in proprietary, commercial software and instead developed software that was free and distributable (as well as having the code publicly available). In 1995, the first version of MySQL was released by a Swedish company (who funded the open source project) – MySQL AB. This software was the first significant database of the Internet and continues to be used by companies like Google (although not for search), Facebook, Twitter, Flickr and Youtube. The open source license gave freedom to website developers and meant they did not have to rely on companies like Oracle and Microsoft. It also worked well with other open source software that created the foundation of the Internet we use today (Linux, Apache, MySQL and PHP (LAMP) became the most common setup for websites). MySQL AB (the company that sponsored the MySQL project) was eventually acquired by Sun Microsystems which was subsequently acquired by Oracle.
In the following years, many other open source databases were created. When Oracle acquired MySQL, a founder of the MySQL project made a fork of the project (i.e. he took the code and started a new project with a different name). This new project was called MariaDB. There are now numerous open source databases that have different licenses and ideologies.
Post-2000 and NoSQL
So far in this article, all the databases mentioned have used the Structured Query Language (SQL) as the main way to retrieve and store data in a database. In 1998, a new term was coined, namely NoSQL. It refers to “non SQL” databases that use other query languages to store and retrieve data. These types of databases have existed since the 1960s, but it was the Web 2.0 revolution that made them come to the attention of the technology world.
Web 1.0 was the first iteration of the Internet when users received and ingested content created by webmasters and their teams. Web 2.0 was the shift to user-generated content and a more user-friendly internet for everyone. Sites like Youtube and social media epitomise this phase of the Internet. For databases, it meant the needs of developers and administrators had changed. There was a vast amount of data being added to the Internet by users every second. Cloud computing unlocked massive storage and processing capabilities and the way we use databases changed.
In this age of technology, the requirements shifted towards simplicity regarding design and scalability due to the vastly growing nature of the new Internet. It was also essential to have 24/7 availability and speed became of utmost importance. Traditional relational databases struggled particularly with the scalability and speed required, and due to NoSQL using different data structures (i.e. key-value, graph, document), it was generally faster. They were also viewed as being more flexible because they did not have the same constraints as traditional relational databases.
There were some disadvantages to NoSQL, in particular it was able to use joins across tables and there was a lack of standardisation. For the new generation of web developers, though, NoSQL was better. It was one of the main reasons for the massive innovations that took place in the first two decades of the 21st century, because website (and later app) development was made much easier and it could cope with the growing nature of the World Wide Web. Relational databases continued to have their place, despite the shift away from them in the online world. Businesses still needed the reliability, consistency and ease of programming for their business systems.
Business intelligence
Computers have transformed the way businesses operate. In the past, decisions were made based on the experience of the most highly paid managers and executives. However, trust in computers and information systems is now at a new high. It is due to the reliability of systems that work in the cloud, advances in technology and the fact that decisions based on fact are proving to be more reliable than those taken based on information from experienced managers and executives (i.e. guesswork).
Business intelligence is the analysis of data and information in an organisation to find insights and trends that can help make decisions. These decisions are not just those taken by executives, but ones taken throughout an organisation. From the smallest, most mundane choices that secretaries and administrators make to decisions that put millions of dollars at stake.
Databases have allowed companies to develop incredibly sophisticated enterprise resource systems (ERP) that gather data from every part of an organisation and store it all in a central database. Data is collected from factories, offices, remote workers, sensors and anywhere that useful and quantifiable data exists. Companies like Oracle and SAP provide solutions that can cost up to $15m for global organisations but which can save them up to 50% in operating costs (taken from the case study: Orange/France Telecom) thanks to improved efficiency and better forecasting.
Business intelligence (BI) systems are not suitable for all types of organisations. The data has to be accurate for the system to give information that can use used in decision making. If an organisation cannot gather the data in real-time (for example, due to a poor connection to the Internet), then BI systems will harm an organisation because the decisions will be based on out-of-date information. The insights that BI systems give have to be carefully chosen and relevant. If not, the insights will be a reinforcement of information that a company already knows. The information has to be timely, so it is available when it is needed. It also has to provide conclusions that are realistic; if a BI system concludes that the competition needs to be eliminated then in most cases, it is a useless conclusion because eliminating the completion is not possible.
Executives and managers can now see real-time information on their organisations and can use this to help them understand more about the decisions they need to make. Systems have to be designed to provide the right information to the right person at the right time. It has led to a trend of firing more experienced managers and replacing them with younger, digitally native employees. One manager can be replaced with three young people for the same cost, and this is a disturbing trend (at least for the older population) that is currently being seen all over the world in developed nations.
Other business databases
Databases also allow organisations to work more effectively with their customers and suppliers. They augment workers, allowing them to do their jobs better and faster. They have also created the digital businesses we use every day, like Amazon and eBay.
Customer Relationship Management (CRM) systems allow organisations to build strong customer profiles from the moment they become a lead (i.e. when a customer first contacts an organisation). They allow for targeted marketing, better communication and are also becoming more connected with social media and other platforms that are commonly used for customer service and marketing.
Supplier management has become much easier thanks to Supply Chain Management (SCM) systems. These allow organisations to do the (previously) impossible. For example, they can fulfil orders made at the last minute and automatically coordinate thousands of suppliers and logistics companies to ensure products reach customers on time. SCM systems can be used to look at the feasibility of a customer request and to ensure that enough of a product will exist at times of peak demand. Large-scale SCM is always a challenge, and even companies like Nintendo and Apple cannot cope with the level of demand their products attract, despite having state-of-the-art systems.
Traditionally, ERP, CRM and SCM systems have been the domain of multinationals with multi-million dollar budgets. The startup culture of the last 20 years has spawned alternatives to the SAPs and Oracles of the world. One of the best examples is Salesforce, a CRM that takes advantage of recent mobile and cloud services and which offers their CRM system using the Software as a Service model (so the software is cloud-based and delivered using apps and web browsers). This type of service is much cheaper than traditional providers, and this means that even the smallest startup can afford to use and benefit from having a customer database. Open source system are also freely available (for example, SugarCRM) and can be deployed with no upfront cost. However, support contracts and hiring of programmers and administrators will never be free.
Big data
Before the cloud brought cheap, affordable storage the only people who could analyse non-structured bulk data were scientists. The European Organisation for Nuclear Research (CERN) has been analysing unstructured data since the 1960s. In the Large Hadron Collider, they have had to analyse particles that collide at 600 million times per second. These analyses are done using a countless number of rapidly taken photos, and this involves a massive amount of storage and sophisticated algorithms. It was these scientists who first started analysing what we now call big data. Traditionally, big data has three primary attributes: volume, variety, and velocity. Volume refers to the amount of data (i.e. a high volume), variety refers to the fact that it is unstructured and velocity refers to the rapid rate at which it is created.
Big data is not just voluminous data (i.e. a lot), it is also data that is unstructured. Data is no longer only produced by employees, sales systems and factories; we now have to deal with data from social media, sensors, video, audio, scanned documents and many other sources. Analysing this data is almost as important as analysing the traditional data we get from our business intelligence systems (indeed, many modern BI systems are beginning to analyse unstructured data sources too).
There are lots of data that we need to analyse today. Typically when the term Big Data is used, petabytes and exabytes of data are being analysed. When this amount of data is stored, there are many difficulties. Storage media fails, computers are unable to cope with the amount of data and writing algorithms to handle all the different types of data is a considerable challenge.
Google was one of the first companies to be confronted with the problem of dealing with a vast amount of data. They wanted a way to improve their batch processing of the World Wide Web, and by running lots of tasks in parallel using many individual computers, they achieved much better results. They published a framework that they named MapReduce. They have now moved on to use another framework for their search, but MapReduce was significant because it resulted in the formation of the open source Hadoop project. They created software that allows anyone to set up large-scale data analytics, either on dedicated hardware or in the cloud.
By analysing this massive amount of data, organisations can examine product launches, consumer reactions, marketing campaigns, and customer support (and much more, of course). In the future, big data will have even more of an impact. The Internet of Things and the new sensors we are going to have in smart factories, connected cars, smart cities and smart homes will mean that there will be much more data generated in every part of society.
Big data affects much more than just business and nuclear research. Police are using Big Data to analyse trends in crime using all the data they have from the past. They are combining this with information from social media, and they are using big data to predict when and where crimes and public disturbances will take place. Google is using searches to predict many things in society. Google Flu Trends used search analysis to predict where outbreaks of the flu virus would occur. They managed to accurately predict outbreaks two weeks before medical experts and traditional warning systems could. Big Data is also being used by meteorologists, seismologists and throughout science to analyse the past and see what the future is likely to hold.
Conclusions
Databases have come a long way since their creation in the 1960s. Initially, they were a solution to the problem of storing and protecting the things we wrote down and making it more accessible at a faster speed. Over time, they have become integral in our society, and we rely on them for banking, security, policing and in providing the services for our digital lives. For companies, business intelligence systems are helping to make more accurate decisions based on real facts, rather than guesswork based on experience. Big Data is helping us find new insights from the data we have generated in the past and will be vital in understanding the society of the future. Without databases, we would still be losing valuable information and the digital revolution would not have happened. The coming industrial revolution, also called Industry 4.0, will be driven by data, and it will transform the lives of every consumer and business in the world.
Bibliography
Harrington, J., & Harrington, J. (2016). Relational database design and implementation : Clearly explained (4th ed.). Amsterdam: Morgan Kaufmann/Elsevier.
Video Case Studies
Orange and Oracle ERP – https://www.youtube.com/watch?v=jsqFQiCmaFs
CERN and Big Data – https://www.youtube.com/watch?v=j-0cUmUyb-Y
#Published

Leave a comment